It is currently very basic: a Python script that will grab all the notes from a specific Tumblr post, filter out the reblog information and add it to a Neo4j graph database. Below are two screenshots of the Neo4j web interface with data loaded, showing the reblog graphs of two different posts. In the second one, you can see that the extra comments people make when reblogging are saved as well.
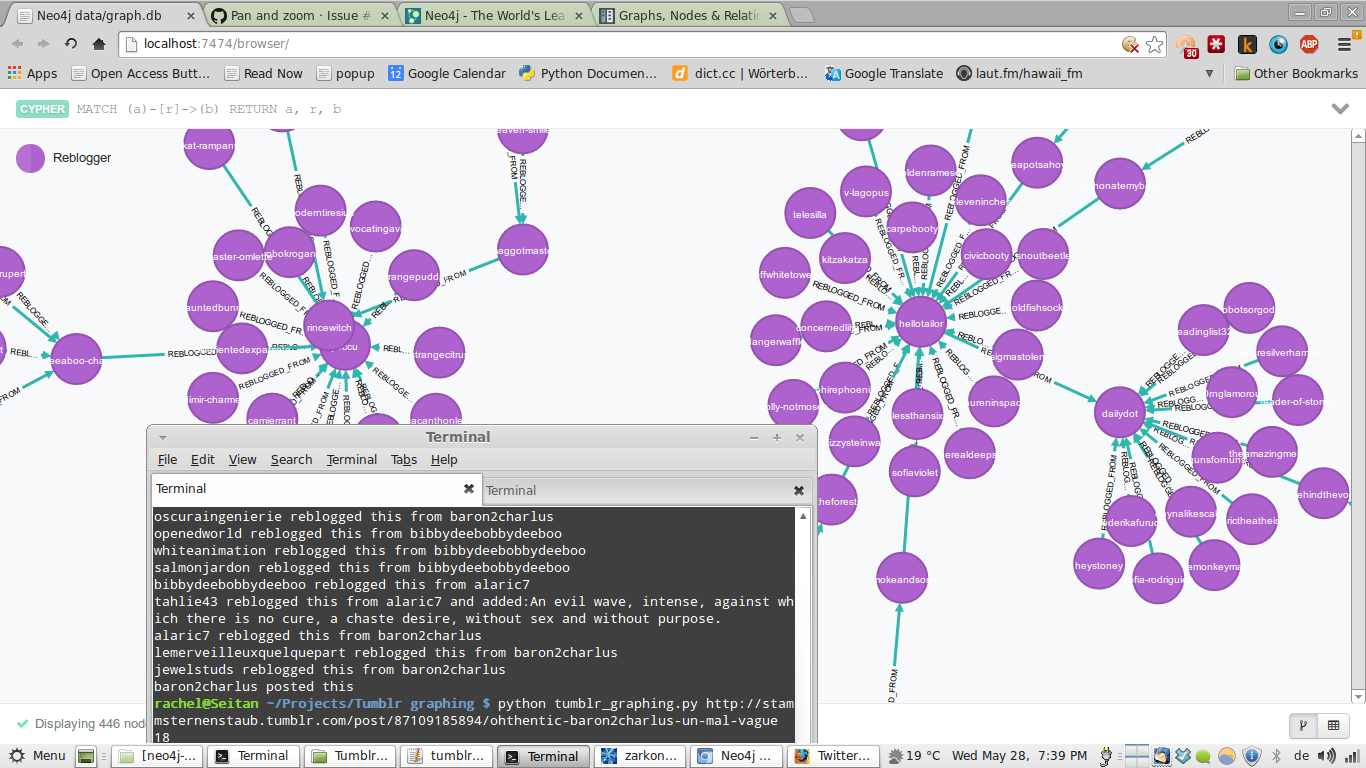
A screenshot showing a graph of Tumblr post reblogs.
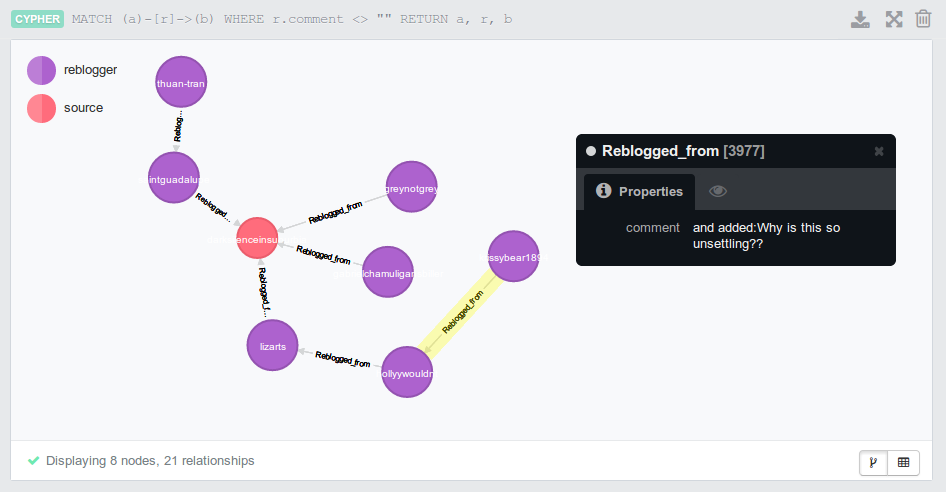
A screenshot showing one particular reblog path for a Tumblr post.
The code is on github here, with some instructions for using it.
I wrote this at a Neo4j hackday, more as a proof of concept than anything else, but if there’s any features you think it should have, do let me know. What I’d really like to do is make a website for visualising reblog graphs on demand. Tumblr itself would probably not like that, though, since this code doesn’t use their API — the API will tell you who reblogged a post, but not whom they reblogged it from, so I’m just scraping the notes list of the post to get that information. Here’s a post about Tumblr analytics, with a few more details about the difficulties.